Web Scraping Part I: Python
This tutorial is written for Python 2.7. Instructions for viewing the page source are based on Google Chrome. Command-line things are for Mac. Note that using the command-line is not a huge part of the tutorial, so this can be easily adapted for use on a Windows machine.
Note: If you have never run a Python script from your computer, you might need to install Python. Additionally, if you don't have them you'll want to install Xcode, command line tools, Homebrew, and PIP. Click here for a tutorial that will walk you through this on a Mac.
In this tutorial we will collect information on Medicare Part D prescription drug plans. The end result will be a CSV file containing information on every part D plan available in every state, with information on monthly premium, deductible, whether there is a “donut hole” coverage gap, tier information, as well as information on the formulary position of every drug (tier number, cost-sharing, and drug usage management)
Here’s a roadmap of we want to do:
- Navigate to the website q1medicare.com
- On this webpage you’ll see a box where you can “Review 2018 Medicare Part D Plans”. Click on AK (Alaska).
- Scroll down to the chart that says “There are 19 Alaska 2018 stand-alone […]. In this chart, you’ll see all of the different plans and information about them. This is the first set of information we want to collect. In our spreadsheet we’re going to collect:
- Plan Name
- Monthly prem.
- Deductible
- (Donut Hole) Gap Coverage
- $0 Prem. with Full LIS?
- Preferred Pharmacy Copay/Coinsurance 30-Day Supply
- Total Formulary Drugs (number)
Here’s what the first row of our output should look like:
 (click to zoom)
(click to zoom)
Our end result will be a spreadsheet containing the above information for every plan in every state.
Now that we have an idea of what we want to do, we’ll start coding it up.
Note: If you need a refresher on how to run a Python script, check out my very short tutorial on how to run a Python script.
Install required Python modules:
The Python modules we will need to run our code are the following:
You will need to install these if they aren’t already on your machine. To do this, go to the command line and type:
pip install selenium
pip install bs4
pip install xlsxwriter
Set up Python file for scraping:
In a new Python file (I’m calling mine “medicare_PDP_scrape.py) add the modules that we will need to the top of the script:
from bs4 import BeautifulSoup
import xlsxwriter
import time
from selenium import webdriver
We need to open the driver that we want to use to visit the websites we plan to scrape. The code below tells Python to use PhantomJS as our webdriver. PhantomJS is basically a web browser that runs in the background.
driver = webdriver.PhantomJS()
Becuase we’ve opened a driver, we need to add a piece of code to the very bottom of our Python file that closes the browser:
driver.quit()
This will be the last line in our file - everything we add to the Python script will go above this line.
Note: There are other webdrivers available such as Chrome or Firefox, but they won't run in the backround - i.e. you will see Python open Google Chrome, go to the website, then close the website.
We will also want to create a variable containing the path of the directory we want to save our spreadsheet in:
save_output_path = '/Users/marisacarlos/Dropbox/mbcarlos.github.io/tutorial_files'
At the top of all of my Python files I define a function that prints a new (blank) line, dashed line, and another new line. I use it to make printing to the console easier to read. After we define the function, we can call it by typing print_line():
def print_line():
print " "
print "----------------------------------------------------------------------------------------------------------------------"
print " "
Write column headers to output worksheet:
Before we start collecting and writing the data to our spreadsheet, we need to specify a name for the Excel workbook (and worksheet within the workbook) that we want to save our output to. Add the following code:
output_workbook = xlsxwriter.Workbook(save_output_path+"/medicare_PDP_scrape.xlsx")
plan_info_worksheet = output_workbook.add_worksheet("plan_info")
The first line creates the workbook, which we can refer to using the variable “output_workbook”. This file will be stored in the path you specified in the variable save_output_path.The second line creates the worksheet within that workbook. When you open the Excel workbook, the worksheet will be named “plan_info”. Within our Python script, we can refer to the worksheet using the variable “plan_info_worksheet”. When we write the output, we will refer to the worksheet (plan_info_worksheet).
Let’s add headers to our excel worksheet in the first row. Note that in the xlsxwriter module, row 0 refers to the first row and column 0 refers to column A.
Because we are going to iterate through rows (i.e. add a new row for every Medicare plan), we will define a variable called row that we will increase everytime we start writing information on a new plan. First we will set it equal to 0, write our headers, and then increase it by 1: row=0
To write the header in the first column, we can type:
```python
plan_info_worksheet.write(row,0,"state")
The write function takes three arguments: The first is the row (which we are specifying with the variable row, which is currently equal to 0), the second is the column (0), and the third is the information you want to write (“state”). We can do this for the next 7 rows:
plan_info_worksheet.write(row,1,"plan_name")
plan_info_worksheet.write(row,2,"monthly_premium")
plan_info_worksheet.write(row,3,"deductible")
plan_info_worksheet.write(row,4,"gap_coverage")
plan_info_worksheet.write(row,5,"zero_prem_full_LIS")
plan_info_worksheet.write(row,6,"preferred_pharmacy_costshare_30day")
plan_info_worksheet.write(row,7,"num_drugs_formulary")
Becuase we opened an Excel workbook, we’ll need to add another line to the very bottom of our Python file that closes the workbook (either before or after driver.quit()):
output_workbook.close()
Now that we’ve set up everything we need to run our Python file and write out output, we can get to the actual web scraping.
As we go through the web scraping steps below, I encourage you to stop and run the file, look at the output, print things to the console, etc. See the troubleshooting section if you need help (get stuck in a loop, etc.)
Set up loop to navigate to the webpage for each state:
If you look at the URL for each state, you’ll notice that the only thing that changes between two states is the abbreviated state code (AK versus AL):
- https://q1medicare.com/PartD-SearchPDPMedicare-2018PlanFinder.php?state=AK#results
- https://q1medicare.com/PartD-SearchPDPMedicare-2018PlanFinder.php?state=AL#results
This will make it easy to loop through the URLs for all states. We can create a list of state codes, and then loop through that list.
Add a line containing a list of state codes:
# state_codes = ["AK", "AL", "AZ", "AR", "CA", "CO", "CT", "DC", "DE", "FL", "GA", "HI", "ID", "IL", "IN", "IA", "KS", "KY", "LA", "ME", "MD", "MA", "MI", "MN", "MS", "MO", "MT", "NE", "NV", "NH", "NJ", "NM", "NY", "NC", "ND", "OH", "OK", "OR", "PA", "RI", "SC","SD", "TN", "TX", "UT", "VT", "VA", "WA", "WV", "WI", "WY"]
state_codes = ["AK"]
I added two lines, one commented out (has the # in front) and one uncommented. It’s much more efficient to write and test our code using the shorter list. If we loop through all the states every time we test the code, it will take much longer and won’t buy us anything. When we’ve finished our code and want to actually collect the data, remove the short list and uncomment the long list.
To loop through the states, type:
for state in state_codes:
print "COLLECTING DATA FOR",state
The code above loops through the list of state codes. This means that in the first loop the variable state will equal “AK”, in the second loop state="AL" and so on until the last loop where state="WY". The print statement just lets us know where we are in the loop. If we run the Python file at this point, we should see the following output in our console:

Now let’s use the state variable to create a new string varaible containing the URL that we want to navigate to. We’ll use the pattern mentioned above (that the URL only differs by the state code):
state_url = "https://q1medicare.com/PartD-SearchPDPMedicare-2018PlanFinder.php?state=" + state + "#results"
print "STATE URL IS:",state_url
Note: Be aware of the indentation used in the previous (and all of the following) commands. The URL variable is created using the state variable, therefore it must be written within the state loop. This means it's indented (4 spaces or the tab button) underneath "for state in state_codes:".
At this point, our Python code should look like this:
from bs4 import BeautifulSoup
import xlsxwriter
import time
from selenium import webdriver
driver = webdriver.PhantomJS()
save_output_path = "/Users/marisacarlos/Dropbox/mbcarlos.github.io/tutorial_files"
def print_line():
print " "
print "----------------------------------------------------------------------------------------------------------------------"
print " "
output_workbook = xlsxwriter.Workbook(save_output_path+"/medicare_PDP_scrape.xlsx")
plan_info_worksheet = output_workbook.add_worksheet("plan_info")
row = 0
plan_info_worksheet.write(row,0,"state")
plan_info_worksheet.write(row,1,"plan_name")
plan_info_worksheet.write(row,2,"monthly_premium")
plan_info_worksheet.write(row,3,"deductible")
plan_info_worksheet.write(row,4,"gap_coverage")
plan_info_worksheet.write(row,5,"zero_prem_full_LIS")
plan_info_worksheet.write(row,6,"preferred_pharmacy_costshare_30day")
plan_info_worksheet.write(row,7,"num_drugs_formulary")
#state_codes = ["AK", "AL", "AZ", "AR", "CA", "CO", "CT", "DC", "DE", "FL", "GA", "HI", "ID", "IL", "IN", "IA", "KS", "KY", "LA", "ME", "MD", "MA", "MI", "MN", "MS", "MO", "MT", "NE", "NV", "NH", "NJ", "NM", "NY", "NC", "ND", "OH", "OK", "OR", "PA", "RI", "SC","SD", "TN", "TX", "UT", "VT", "VA", "WA", "WV", "WI", "WY"]
state_codes = ["AK"]
for state in state_codes:
print "COLLECTING DATA FOR",state
state_url = "https://q1medicare.com/PartD-SearchPDPMedicare-2018PlanFinder.php?state=" + state + "#results"
print "STATE URL IS:",state_url
output_workbook.close()
driver.quit()
Extract and parse the HTML:
Now that we have the URL, we can tell Python to go to that website and get all of the underlying HTML code from that webpage. To do that type:
driver.get(state_url)
It’s also a good habit to get into to tell Python to sleep for a second (or more) after you visit a website. Some websites have rate limits and this will help with that (though it is not fail safe):
time.sleep(1)
Next, we want to feed the HTML from the page into Beautiful Soup. Beautiful Soup is a Python library that lets us to systematically pull information out of the HTML code. To do this, add:
soup = BeautifulSoup(driver.page_source,"lxml")
Now all of our HTML code for the Alaska webpage is stored in the variable soup. We can use now use functions from the Beautiful Soup library to collect the data we need.
The next part is the trickest part of web scraping. We need to figure out where the information we want to collect is and figure out a well to tell Python what information we want. We’ll start by looking at the page source. In Google Chrome paste the following into your address bar:
view-source:https://q1medicare.com/PartD-SearchPDPMedicare-2018PlanFinder.php?state=AK#results
Notice this is just the website prefixed with view-source:. You can also get to this by going to the website, right clicking anywhere, and selecting “view page source.”
The information you’ll see in the page source is the same information that is contained in our “soup”. You can print the soup in an easy-ish to read way (i.e. “prettify” it):
print soup.prettify()
If you run the Python file you can see that the information in the variable “soup” is the same as the information in the page source on Google Chrome.
Scrolling through the page source, it’s clear that there is a lot of information we don’t need. We want to find a way to identify each row of the table in the page source. When I looked at the webpage I noticed that every row of the table has the text “Preferred Generic”. If I search the page I can see that this text only occurs in the table, and it occurs in every single row.
I can search for this text in the page source to glean some insight into what tags contain the information I want:
 (click to zoom)
(click to zoom)
The screenshot above shows the entire tag, which contains all of the information that we need. It is a <tr> tag - which we know because it starts with <tr> and ends with </tr>:
 (click to zoom)
(click to zoom)
All of the information we are looking for from a given row is contained within the tag:
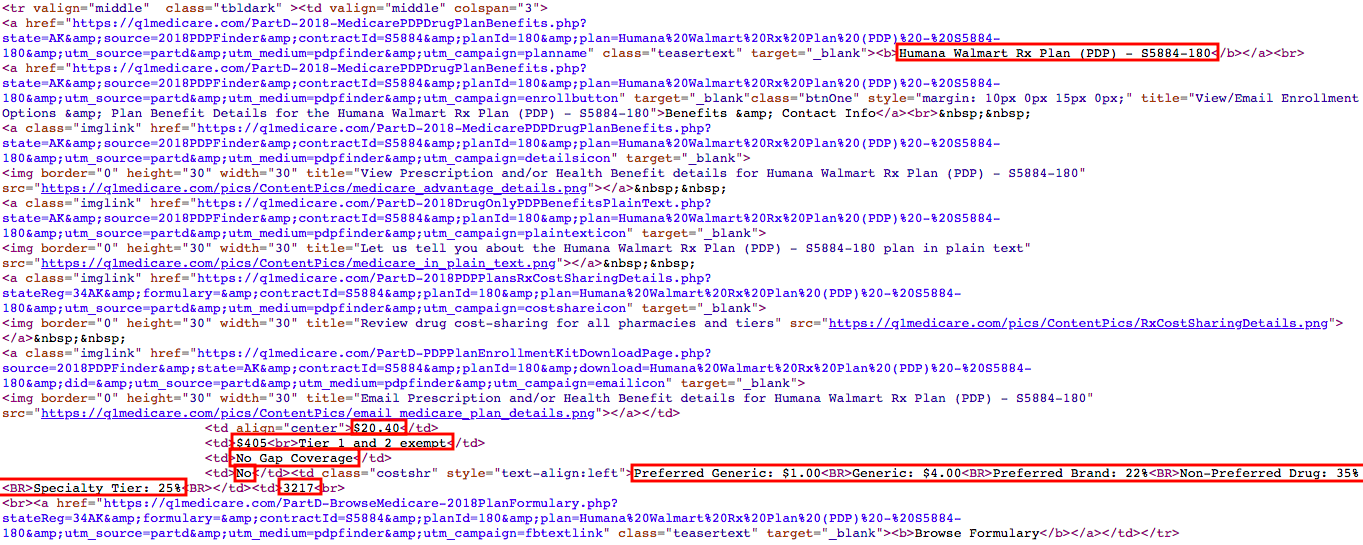 (click to zoom)
(click to zoom)
The screenshot above is the <tr> tag for the first row of the table. Scroll through the page source and see if you can identify the other <tr> tags which contain the information for the other rows.
Note: There are many different types of tags, but the basic structure that you need to know is that tag X starts with <X> and ends with </X>. To see a list of different tag types, see w3schools.com It's not super important to understand what each tag type does, it's just important to know how to identify them in the code.
After looking through the <tr> tags, it looks like each <tr> tag containing the row information has one of the following attributes:
valign="middle" class="tbldark"
or
valign="middle" class="tbllight"
Luckily for us, it looks like the <tr> tags with attribute valign="middle" are only used for the rows in the table with the data we want. Becuase of this we can pull out all the TR tags with this attribute. To do this, we’ll use Beautiful Soup’s find_all command:
soup.find_all('tr',attrs={"valign":"middle"})
(Note that you do not need to add the above line to your Python file - we’ll get to that below.)
The find_all command pull tags out of the soup. The first argument we give find_all tells it to pull out a specific type of tag - in our case all of the <tr> tags. The second argument narrows down the <tr> tags to those containing the attribute valign="middle".
Note: The find_all command does not require a tag type or attributes and has many more functions than illustrated above. Explore the documentation to see how else you can use find_all and other Beautiful Soup commands
We can see how many of these types of <tr> tags exist in the document by printing the length of the list (i.e. the number of elements in the list, where an element is a single <tr> tag):
print "Number of tags meeting this criteria:"
print len(soup.find_all('tr',attrs={"valign":"middle"}))
We can see that this number is 19, which is the number of rows in the table for Alaska. At this point it should be safe to assume we are pulling out the information we need and nothing more.
We can loop through all of these tags and print each one using the following code:
for tr_tag in soup.find_all('tr',attrs={"valign":"middle"}):
print_line() #remember this just prints a line so we can read the output easier
print tr_tag
The first time we go through this loop the variable tr_tag will contain all the information in the Humana Walmart Rx Plan (PDP) - S5884-180 row. In the second loop it will have all the information in the Express Scripts Medicare - Saver (PDP) - S5660-250 row, and so on.
We can see that within each <tr> tag there are a bunch of <td> tags. We can also see this if we inspect the page source a little more closely:
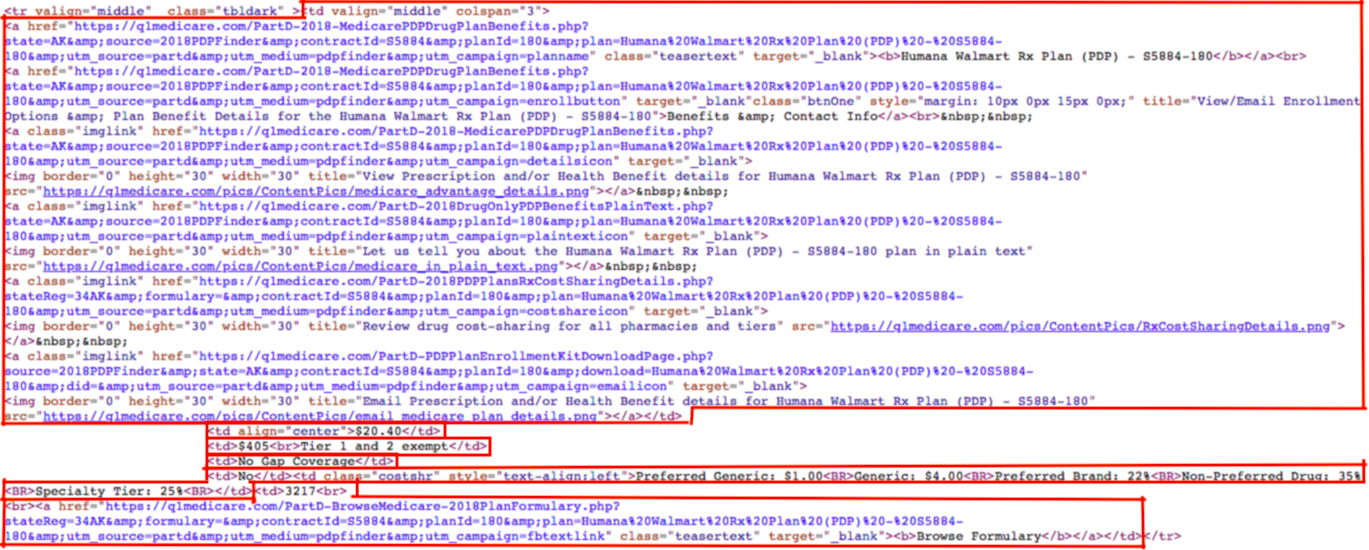 (click to zoom)
(click to zoom)
You’ll also notice that within some of the <td> tags, there are <a> tags, which define hyperlinks. For example, here are the <a> tags in the first <td> tag:
 (click to zoom)
(click to zoom)
The <a> tags would be useful if we wanted to get, for example, the link behind the browse formulary text (though we won’t be doing that in this tutorial).
The final thing we want to do before we can write it all to our worksheet is to loop through the columns of the table. As we saw in the earlier screenshot, the <td> tags within each <tr> tag contain the column information we are looking for - plan name, premium, deductible, etc. To extract this information, let’s create our third and final loop:
for td_tag in tr_tag.find_all('td'):
print_line()
print td_tag
In each loop, the variable td_tag contains all the information for a specific column of the current row. We want to get just the text and remove all of the HTML coding. To do this, we can append the command get_text() to our variable td_tag:
print td_tag.get_text()
We also want to remove the leading and trailing blanks by adding the command strip():
print td_tag.get_text().strip()
Finally, we want to remove the text “Benefits & Contact Info” and “Browse Formulary” that shows up in the first and last columns. We don’t need this in our output, so let’s remove it using two replace() commands, which will replace “Benefits & Contact Info” with “” (nothing) as well as “Browse Formulary”.
print td_tag.get_text().strip().replace("Benefits & Contact Info","").replace("Browse Formulary","")
To make it easier to comprehend when we write it to our worksheet, I’m going to save the string in a variable called write_cell_value:
write_cell_value = td_tag.get_text().strip().replace("Benefits & Contact Info","").replace("Browse Formulary","")
Now that we have the information we want in the format we want, we can begin writing it to our worksheet. But first let’s recap where we are and what our Python code should look like at this point.
Our three nested loops are:
- State loop (
for state in state_codes:): Loops through all the different states (in the first loop state=”AK”, second state=”AL, and so on.) <tr>tag loop (fortr_tag in soup.find_all('tr',{"valign":"middle"}):): Loops through the<tr>tags - each<tr>tag has the information for an entire row of the the table. (In the first loop,tr_taghas all the info in the Humana Walmart Rx Plan (PDP) - S5884-180 row; in the second looptr_taghas all the info in the Express Scripts Medicare - Saver (PDP) - S5660-250 row, and so on.)<td>tag loop (for td_tag in tr_tag.find_all(‘td’):): Loops through the<td>tags within each<tr>tag. Each<td>tag has the information for a single cell of the table.
Here’s what our code should look like so far:
from bs4 import BeautifulSoup
import xlsxwriter
import time
from selenium import webdriver
driver = webdriver.PhantomJS()
save_output_path = "/Users/marisacarlos/Dropbox/mbcarlos.github.io/tutorial_files"
def print_line():
print " "
print "----------------------------------------------------------------------------------------------------------------------"
print " "
output_workbook = xlsxwriter.Workbook(save_output_path+"/medicare_PDP_scrape.xlsx")
plan_info_worksheet = output_workbook.add_worksheet("plan_info")
row = 0
plan_info_worksheet.write(row,0,"state")
plan_info_worksheet.write(row,1,"plan_name")
plan_info_worksheet.write(row,2,"monthly_premium")
plan_info_worksheet.write(row,3,"deductible")
plan_info_worksheet.write(row,4,"gap_coverage")
plan_info_worksheet.write(row,5,"zero_prem_full_LIS")
plan_info_worksheet.write(row,6,"preferred_pharmacy_costshare_30day")
plan_info_worksheet.write(row,7,"num_drugs_formulary")
#state_codes = ["AK", "AL", "AZ", "AR", "CA", "CO", "CT", "DC", "DE", "FL", "GA", "HI", "ID", "IL", "IN", "IA", "KS", "KY", "LA", "ME", "MD", "MA", "MI", "MN", "MS", "MO", "MT", "NE", "NV", "NH", "NJ", "NM", "NY", "NC", "ND", "OH", "OK", "OR", "PA", "RI", "SC","SD", "TN", "TX", "UT", "VT", "VA", "WA", "WV", "WI", "WY"]
state_codes = ["AK"]
for state in state_codes:
print "COLLECTING DATA FOR",state
state_url = "https://q1medicare.com/PartD-SearchPDPMedicare-2018PlanFinder.php?state=" + state + "#results"
print "STATE URL IS:",state_url
driver.get(state_url)
time.sleep(1)
soup = BeautifulSoup(driver.page_source,"lxml")
print soup.prettify()
print "Number of tags meeting this criteria:"
print len(soup.find_all('tr',attrs={"valign":"middle"}))
for tr_tag in soup.find_all('tr',attrs={"valign":"middle"}):
row += 1
print_line() #remember this just prints a line so we can read the output easier
print tr_tag
col = 0
for td_tag in tr_tag.find_all('td'):
print_line()
print td_tag.get_text().strip().replace("Benefits & Contact Info","").replace("Browse Formulary","")
write_cell_value = td_tag.get_text().strip().replace("Benefits & Contact Info","").replace("Browse Formulary","")
output_workbook.close()
driver.quit()
Output the data to the worksheet:
Every time we go to a new row of a table, we need to increase our variable row by 1. We will use this variable to tell Python which row of our worksheet to write to. We can add the following code right underneath our <tr> tag loop:
row += 1
The top of this loop should now be:
for tr_tag in soup.find_all('tr',attrs={"valign":"middle"}):
row += 1
print_line()
print tr_tag
Similar to our row variable, we want to create a variable that we can use to tell Python which column of our worksheet to write the data to. Right above our <td> loop, add:
col = 0
The top of this loop should now be:
col = 0
for td_tag in tr_tag.find_all('td'):
print_line()
The column variable will return to 0 every time we go through a new row of the table. This allows us to return back to column A after we’ve finished scraping the data in a row of the table.
Before we write the plan name, premium, etc. we want to add the name of the state to the first column. We can do this using an if statement. If col==0, then we have just starting a new row and therefore need to write the name of the state:
if col==0:
plan_info_worksheet.write(row,col,state)
After we’ve written the state into the first column, we need to increase our col variable by 1 so that we can write to the next column:
col+=1
Finally we can write the plan information into the other columns (plan name, premium, etc.). Remember that we stored this information in the variable called write_cell_value:
plan_info_worksheet.write(row,col,write_cell_value)
The very last thing we need to do to collect all of the data is remove the short state_codes list and uncomment the longer list.
Our final Python file should look like:
from bs4 import BeautifulSoup
import xlsxwriter
import time
from selenium import webdriver
driver = webdriver.PhantomJS()
save_output_path = "/Users/marisacarlos/Dropbox/mbcarlos.github.io/tutorial_files"
def print_line():
print " "
print "----------------------------------------------------------------------------------------------------------------------"
print " "
output_workbook = xlsxwriter.Workbook(save_output_path+"/medicare_PDP_scrape.xlsx")
plan_info_worksheet = output_workbook.add_worksheet("plan_info")
row = 0
plan_info_worksheet.write(row,0,"state")
plan_info_worksheet.write(row,1,"plan_name")
plan_info_worksheet.write(row,2,"monthly_premium")
plan_info_worksheet.write(row,3,"deductible")
plan_info_worksheet.write(row,4,"gap_coverage")
plan_info_worksheet.write(row,5,"zero_prem_full_LIS")
plan_info_worksheet.write(row,6,"preferred_pharmacy_costshare_30day")
plan_info_worksheet.write(row,7,"num_drugs_formulary")
state_codes = ["AK", "AL", "AZ", "AR", "CA", "CO", "CT", "DC", "DE", "FL", "GA", "HI", "ID", "IL", "IN", "IA", "KS", "KY", "LA", "ME", "MD", "MA", "MI", "MN", "MS", "MO", "MT", "NE", "NV", "NH", "NJ", "NM", "NY", "NC", "ND", "OH", "OK", "OR", "PA", "RI", "SC","SD", "TN", "TX", "UT", "VT", "VA", "WA", "WV", "WI", "WY"]
#state_codes = ["AK"]
for state in state_codes:
print "COLLECTING DATA FOR",state
state_url = "https://q1medicare.com/PartD-SearchPDPMedicare-2018PlanFinder.php?state=" + state + "#results"
print "STATE URL IS:",state_url
driver.get(state_url)
time.sleep(1)
soup = BeautifulSoup(driver.page_source,"lxml")
print soup.prettify()
print "Number of tags meeting this criteria:"
print len(soup.find_all('tr',attrs={"valign":"middle"}))
for tr_tag in soup.find_all('tr',attrs={"valign":"middle"}):
row += 1
print_line() #remember this just prints a line so we can read the output easier
print tr_tag
col = 0
for td_tag in tr_tag.find_all('td'):
print_line()
print td_tag.get_text().strip().replace("Benefits & Contact Info","").replace("Browse Formulary","")
write_cell_value = td_tag.get_text().strip().replace("Benefits & Contact Info","").replace("Browse Formulary","")
if col==0:
plan_info_worksheet.write(row,col,state)
col+=1
plan_info_worksheet.write(row,col,write_cell_value)
output_workbook.close()
driver.quit()
You should now be able to open the workbook and see something like the following:
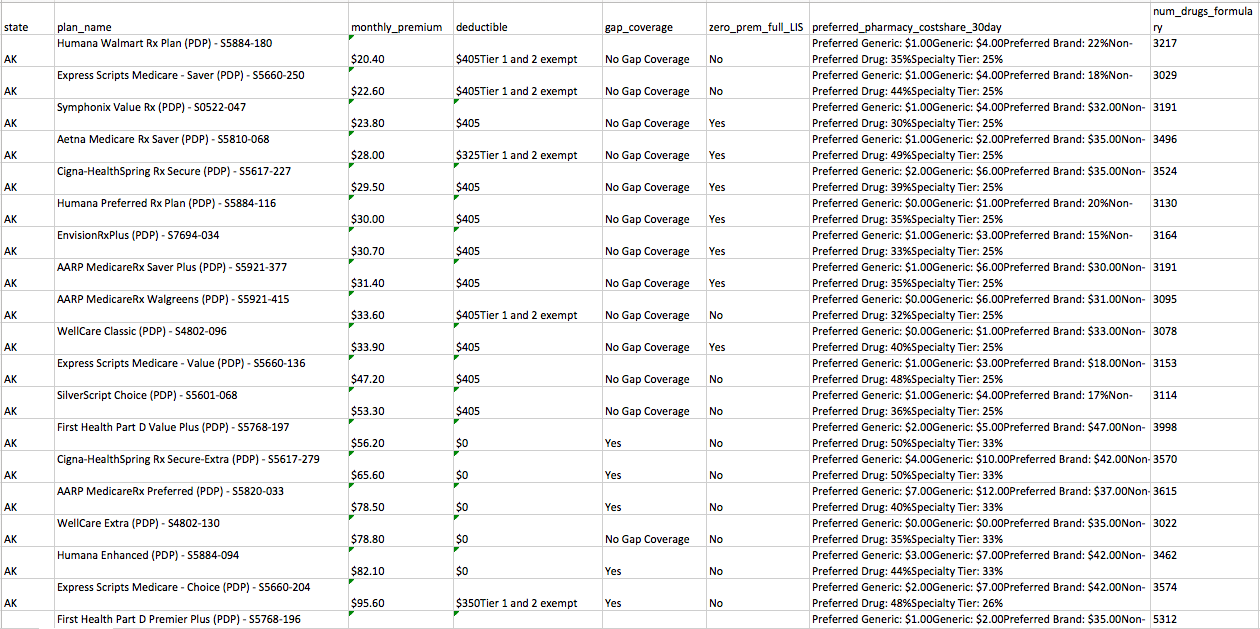 (click to zoom)
(click to zoom)
Troubleshooting:
Get stuck in a loop or run something that you didn’t mean to? You can terminate the Python command by doing the following. First open a new tab or window in your terminal. Then type:
ps aux | grep python
This will display a list of processes containing the term “python”. Look for the process containing the command you issued (in my case it says:)
 (click to zoom)
(click to zoom)
Figure out what the process ID is. In the example above the PID is 6380, so to stop this process I issue the command:
kill 6380
When you go back to the window where you issued the Python command you’ll see:
Terminated: 15